Introduction to the TBSignatureProfiler
Aubrey Odom
Program in Bioinformatics, Boston University, Boston, MAaodom@bu.edu
W. Evan Johnson
Division of Infectious Disease, Center for Data Science, Rutgers University – New Jersey Medical School, Newark, NJ, USAwj183@njms.rutgers.edu
April 30, 2025
Source:vignettes/rmd/TBSig_Vignette.Rmd
TBSig_Vignette.RmdIntroduction to the TBSignatureProfiler
Tuberculosis (TB) is the leading cause of infectious disease mortality worldwide, causing on average nearly 1.4 million deaths per year. A consistent issue faced in controlling TB outbreak is difficulty in diagnosing individuals with particular types of TB infections for which bacteria tests (e.g., via GeneXpert, sputum) prove inaccurate. As an alternative mechanism of diagnosis for these infections, researchers have discovered and published multiple gene expression signatures as blood-based disease biomarkers. In this context, gene signatures are defined as a combined group of genes with a uniquely characteristic pattern of gene expression that occurs as a result of a medical condition. To date, more than 75 signatures have been published by researchers, though most have relatively low cross-condition validation (e.g., testing TB in samples from diverse geographic and comorbidity backgrounds). Furthermore, these signatures have never been formally collected and made available as a single unified resource.
We aim to provide the scientific community with a resource to access these aggregated signatures and to create an efficient means for their visual and quantitative comparison via open source software. This necessitated the development of the TBSignatureProfiler, a novel R package which delivers a computational profiling platform for researchers to characterize the diagnostic ability of existing signatures in multiple comorbidity settings. This software allows for signature strength estimation via several enrichment methods and subsequent visualization of single- and multi-pathway results. Its signature evaluation functionalities include signature profiling, AUC bootstrapping, and leave-one-out cross-validation (LOOCV) of logistic regression to approximate TB samples’ status. Its plotting functionalities include sample-signature score heatmaps, bootstrap AUC and LOOCV boxplots, and tables for presenting results.
More recently, the TBSignatureProfiler has undertaken a new role in
analyzing signatures across multiple chronic airway diseases, the most
recent being COVID-19 (see the COVIDsignatures object). As
we grow and expand the TBSignatureProfiler, we hope to add signatures
from multiple diseases to improve the package’s utility in the area of
gene signature comparison.
Installation
In order to install the TBSignatureProfiler from Bioconductor, run the following code:
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("TBSignatureProfiler")Compatibility with SummarizedExperiment objects
While the TBSignatureProfiler often allows for the form of a
data.frame or matrix as input data, the most
ideal form of input for this package is that of the
SummarizedExperiment object. This is an amazing data
structure that is being developed by the Bioconductor team as part of
the SummarizedExperiment
package. It is able to store data matrices along with annotation
information, metadata, and reduced dimensionality data (PCA, t-SNE,
etc.). To learn more about proper usage and context of the
SummarizedExperiment object, you may want to take a look at
the package
vignette. A basic understanding of the assay and
colData properties of a SummarizedExperiment
will be useful for the purposes of this vignette.
To install the SummarizedExperiment package, run the
following code:
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("SummarizedExperiment")A Tutorial for the TBSignatureProfiler
Run Shiny App
This command is to start the TBSignatureProfiler shiny app. The Shiny app implements several functions described in this vignette.
TBSPapp()The basic functions of the shiny app are also included in the command line version of the TBSignatureProfiler, which is the focus of the remainder of this vignette.
Load dataset from a SummarizedExperiment object
In this tutorial, we will work with HIV and Tuberculosis (TB) gene
expression data in a SummarizedExperiment format. This
dataset is included in the TBSignatureProfiler package and can be loaded
into the global environment with data("TB_hiv"). The 31
samples in the dataset are marked as either having both TB and HIV
infection, or HIV infection only.
We begin by examining the dataset, which contains a matrix of counts information (an “assay” in SummarizedExperiment terms) and another matrix of meta data information on our samples (the “colData”). We will also generate a few additional assays; these are the log(counts), the counts per million (CPM) reads mapped, and the log(CPM) assays.
## HIV/TB gene expression data, included in the package
hivtb_data <- TB_hiv
### Note that we have 25,369 genes, 33 samples, and 1 assay of counts
dim(hivtb_data)## [1] 25369 31
# We start with only one assay
assays(hivtb_data)## List of length 1
## names(1): countsWe now make a log counts, CPM and log CPM assay.
## Make a log counts, CPM and log CPM assay
hivtb_data <- mkAssay(hivtb_data, log = TRUE, counts_to_CPM = TRUE)
### Check to see that we now have 4 assays
assays(hivtb_data)## List of length 4
## names(4): counts log_counts counts_cpm log_counts_cpmProfile the data
The TBSignatureProfiler enables comparison of multiple Tuberculosis
gene signatures. The package currently contains information on 79
signatures for comparison. The default signature list object for most
functions here is TBsignatures, although a list with
publication-given signature names is also available in the
TBcommon object. Data frames of annotation information for
these signatures, including information on associated disease and tissue
type, can be accessed as sigAnnotData and
common_sigAnnotData respectively.
With the runTBSigProfiler function, we are able to score
these signatures with a selection of algorithms, including gene
set variation analysis (GSVA) (Hänzelmann et al, 2013), single-sample
GSEA (ssGSEA) (Barbie et al, 2009), and the ASSIGN
pathway profiling toolkit (Shen et al, 2015). For a complete list of
included scoring methods, run ?runTBsigProfiler in the
terminal.
Here, we evaluate all signatures included in the package with ssGSEA. Paraphrasing from the ssGSEA documentation, for each pairing of one of the 31 samples and its gene set, ssGSEA calculates a separate enrichment score independent of the phenotypic labeling (in this case, whether a sample has HIV/TB, or HIV only). The single sample’s gene expression profile is then transformed to a gene set enrichment profile. A score from the set profile represents the activity level of the biological process in which the gene set’s members are coordinately up- or down-regulated.
## [1] "Anderson_42" "Anderson_OD_51" "Berry_393"
## [4] "Berry_OD_86" "Blankley_380" "Blankley_5"
## [7] "Bloom_OD_144" "Bloom_RES_268" "Bloom_RES_558"
## [10] "Chen_5" "Chen_HIV_4" "Chendi_HIV_2"
## [13] "Darboe_RISK_11" "Dawany_HIV_251" "Duffy_23"
## [16] "Esmail_203" "Esmail_82" "Esmail_OD_893"
## [19] "Estevez_133" "Estevez_259" "Francisco_OD_2"
## [22] "Gjoen_10" "Gjoen_7" "Gliddon_2_OD_4"
## [25] "Gliddon_HIV_3" "Gliddon_OD_3" "Gliddon_OD_4"
## [28] "Gong_OD_4" "Heycken_FAIL_22" "Hoang_OD_13"
## [31] "Hoang_OD_20" "Hoang_OD_3" "Huang_OD_13"
## [34] "Jacobsen_3" "Jenum_8" "Kaforou_27"
## [37] "Kaforou_OD_44" "Kaforou_OD_53" "Kaul_3"
## [40] "Kulkarni_HIV_2" "Kwan_186" "LauxdaCosta_OD_3"
## [43] "Lee_4" "Leong_24" "Leong_RISK_29"
## [46] "Li_3" "Long_RES_10" "Maertzdorf_15"
## [49] "Maertzdorf_4" "Maertzdorf_OD_100" "Natarajan_7"
## [52] "PennNich_RISK_6" "Qian_OD_17" "Rajan_HIV_5"
## [55] "Roe_3" "Roe_OD_4" "Sambarey_HIV_10"
## [58] "Singhania_OD_20" "Sivakumaran_11" "Sloot_HIV_2"
## [61] "Suliman_4" "Suliman_RISK_2" "Suliman_RISK_4"
## [64] "Sweeney_OD_3" "Tabone_OD_11" "Tabone_RES_25"
## [67] "Tabone_RES_27" "Thompson_9" "Thompson_FAIL_13"
## [70] "Thompson_RES_5" "Tornheim_71" "Tornheim_RES_25"
## [73] "Vargas_18" "Vargas_42" "Verhagen_10"
## [76] "Walter_51" "Walter_PNA_119" "Walter_PNA_47"
## [79] "Zak_RISK_16" "Zhao_NANO_6"
## We can use all of these signatures for further analysis
siglist_hivtb <- names(TBsignatures)
## Run the TBSignatureProfiler to score the signatures in the data
out <- capture.output(ssgsea_result <- runTBsigProfiler(input = hivtb_data,
useAssay = "log_counts_cpm",
signatures = TBsignatures,
algorithm = "ssGSEA",
combineSigAndAlgorithm = TRUE,
parallel.sz = 1))## Parameter update_genes is TRUE. Gene names will be updated.## The following signatures have <2 genes that coincide with the genes in the given sample and will not be scored: Chendi_HIV_2## Running ssGSEA
## Remove any signatures that were not scored
TBsignatures <- subset(TBsignatures, !(names(TBsignatures) %in% c("Chendi_HIV_2")))When a SummarizedExperiment is the format of the input
data for runTBsigprofiler, the returned object is also of
the SummarizedExperiment. The scores will be returned as a
part of the colData.
Below, we subset the data to compare the enrichment scores for the Anderson_42, Anderson_OD_51, and Zak_RISK_16 signatures.
Signature Scores
Visualization with TBSignatureProfiler Plots
Heatmap with all Signatures
Commonly, enrichment scores are compared across signatures by means
of a heatmap combined with clustering methods to group samples and/or
scores. The signatureHeatmap function uses the information
from the score data to visualize changes in gene expression across
samples and signatures (or genes, if only one signature is
selected).
Here, the columns of the heatmap represent samples, and rows represent signatures. Rows are split according to annotation data with associated signature disease type. As we move across the columns, we see different patterns of gene expression as indicated by the varying color and intensity of individual rectangles. In the top bar, the solid red represents a sample is HIV infected only, and solid blue indicates that the sample is both HIV and TB infected. In the gradient area of the heatmap, the scaled scores are associated with either up-regulated or down-regulated genes.
# Colors for gradient
colors <- RColorBrewer::brewer.pal(6, "Spectral")
col.me <- circlize::colorRamp2(seq(from = -2, to = 2,
length.out = 6), colors)
signatureHeatmap(ssgsea_result, name = "Heatmap of Signatures,
ssGSEA Algorithm",
signatureColNames = names(TBsignatures),
annotationColNames = "Disease",
scale = TRUE,
showColumnNames = TRUE,
choose_color = col.me)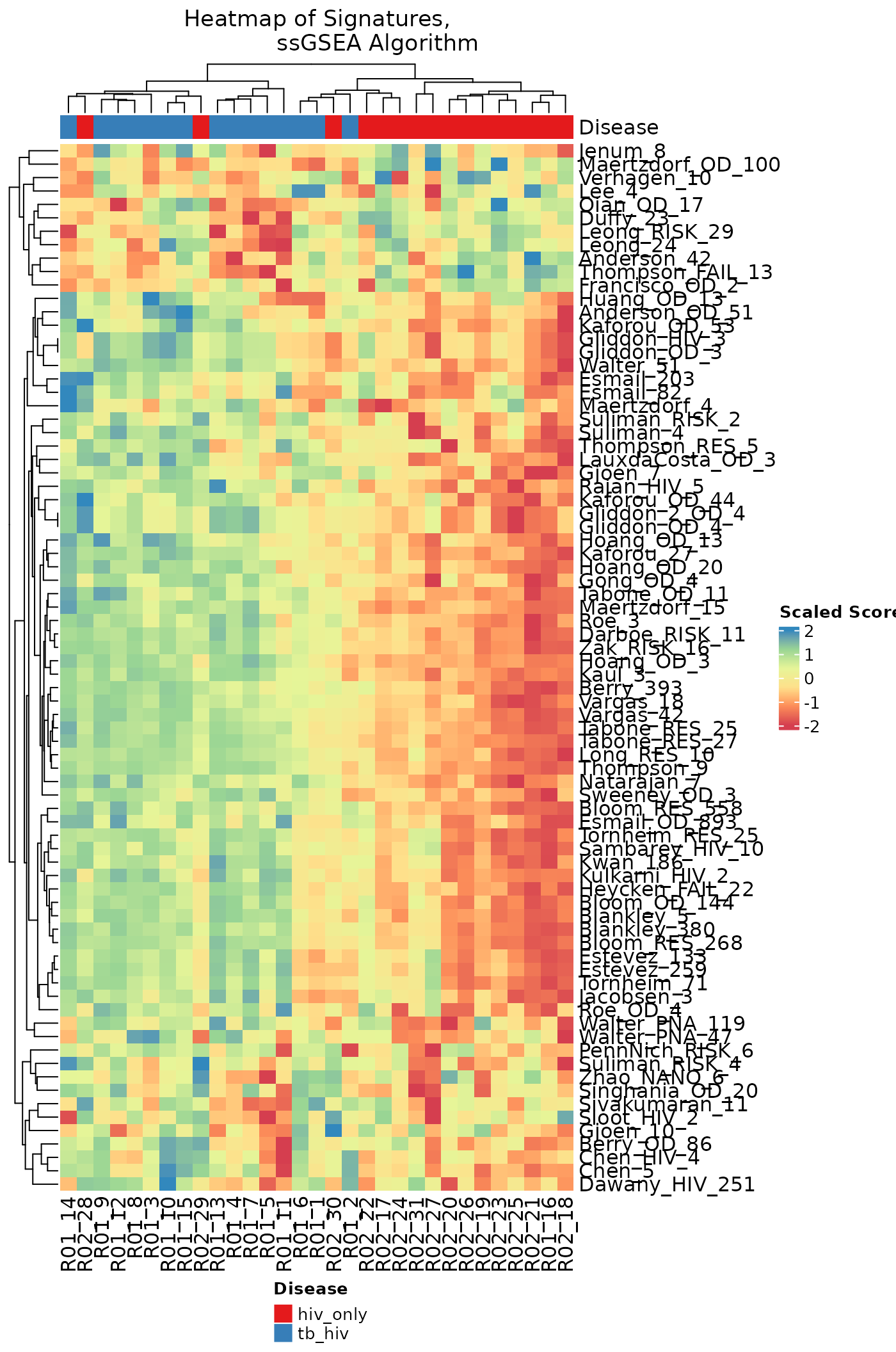
Boxplots of Scores, All Signatures
Another method of visualization for scores is that of boxplots. When
multiple signatures in the input data are to be compared, the
signatureBoxplot function takes the scores for each
signature and produces an individual boxplot, with jittered points
representing individual sample scores. For this specific example, it is
clear that some signatures do a better job at differentiating the TB/HIV
and HIV only samples than others, as seen by overlapping or separate
spreads of the adjacent boxplots.
signatureBoxplot(inputData = ssgsea_result,
name = "Boxplots of Signatures, ssGSEA",
signatureColNames = names(TBsignatures),
annotationColName = "Disease", rotateLabels = FALSE)
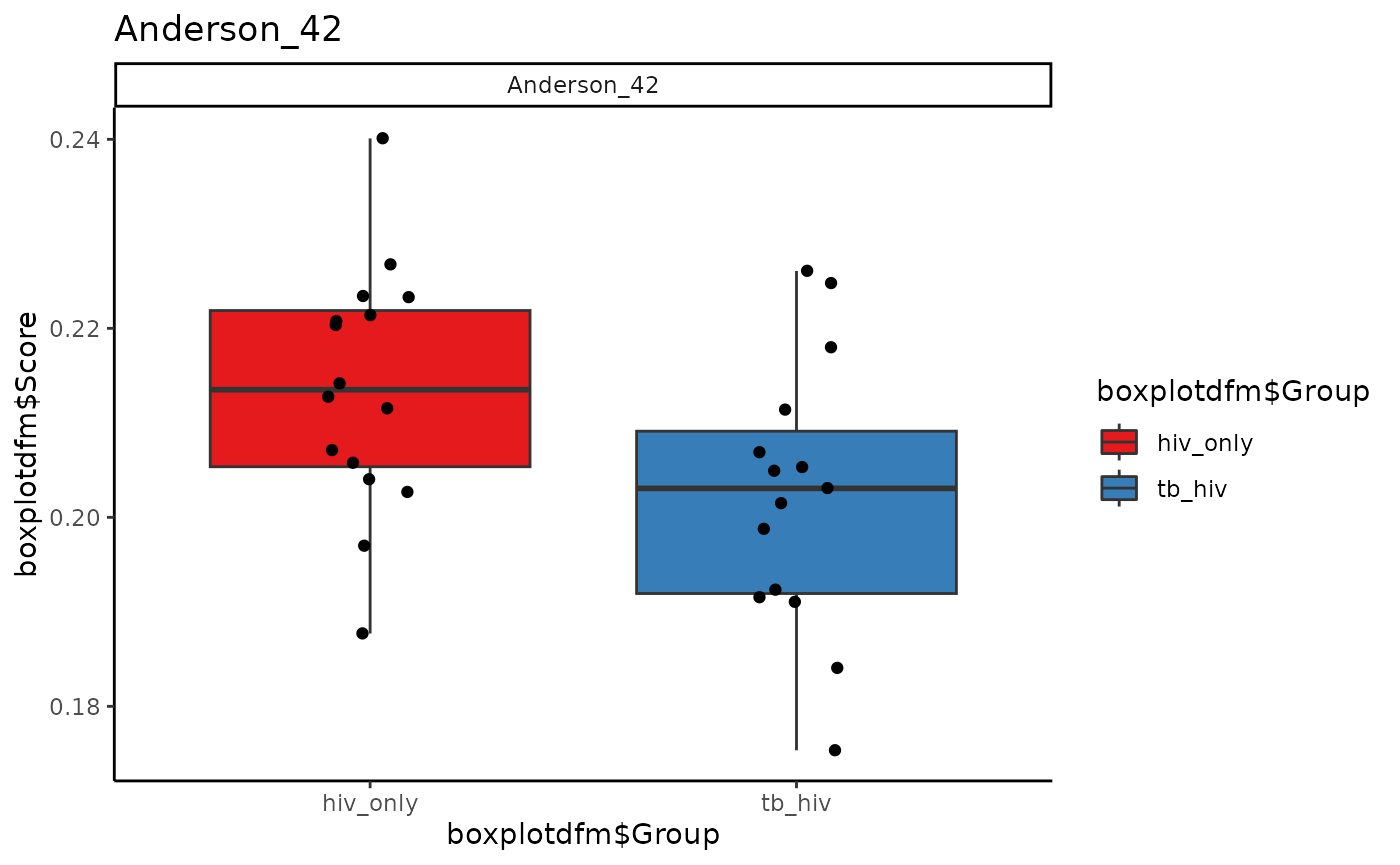
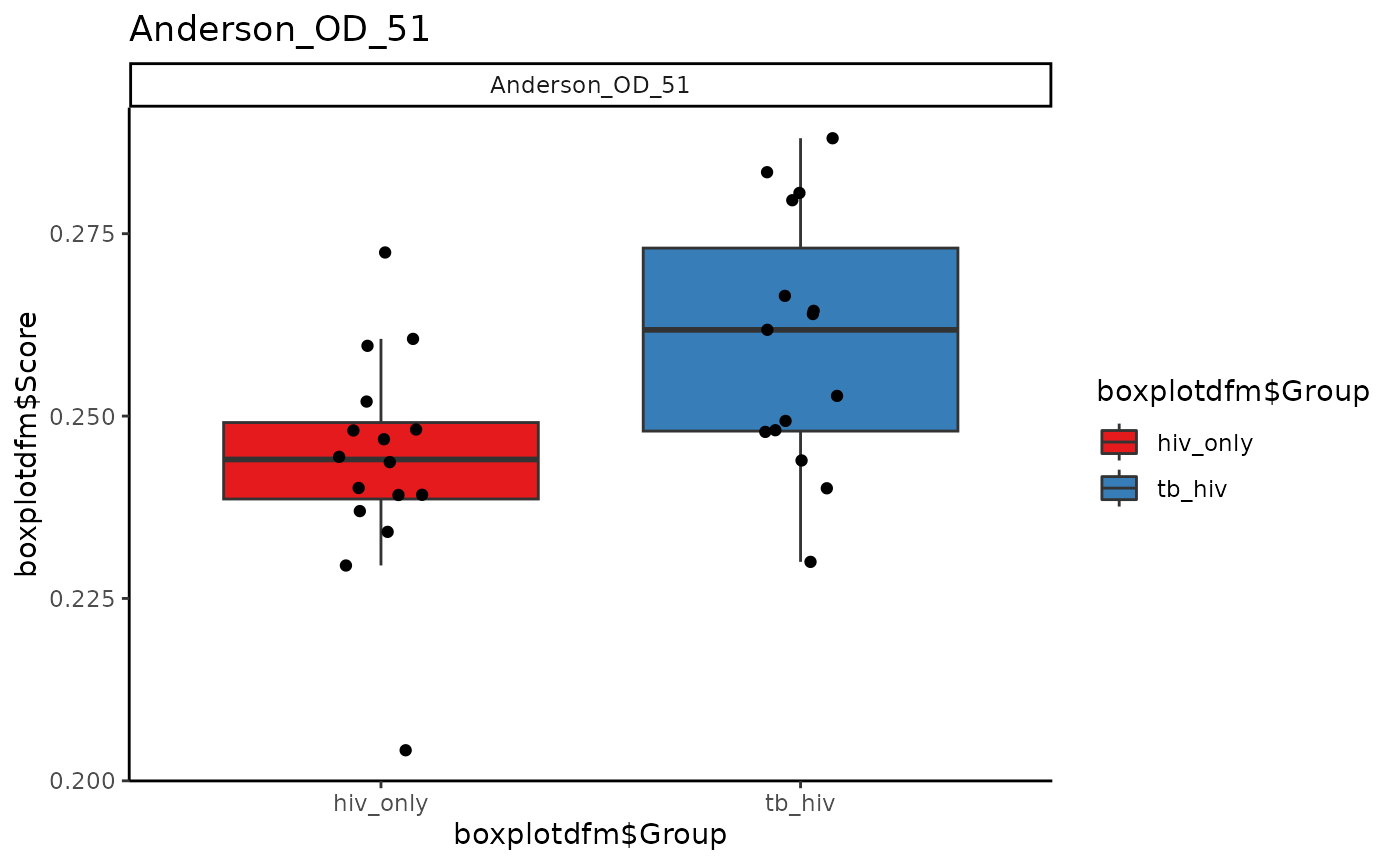
Boxplots of Scores, Individual Signatures
If only one boxplot of a signature is desired, then that signature
alone should be specified in signatureColNames. Otherwise,
an array of plots for all signatures will be produced. Here we use the
signatures Anderson_42, Anderson_OD_51, and Zak_RISK_16.
for (i in sigs){
cat("####", i, "\n")
print(signatureBoxplot(ssgsea_result, name = i, signatureColNames = i,
annotationColName = c("Disease")))
cat("\n\n")
}

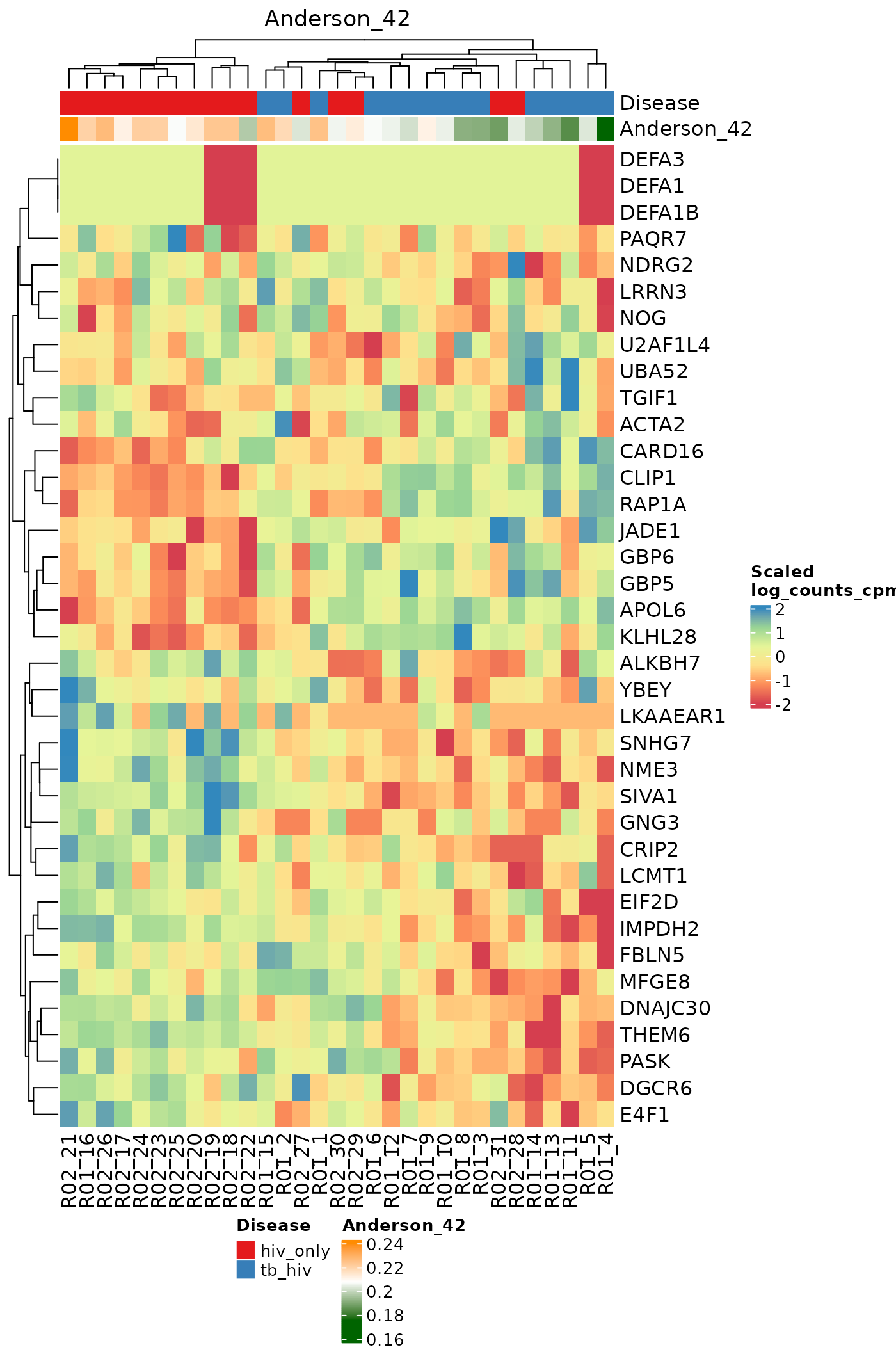
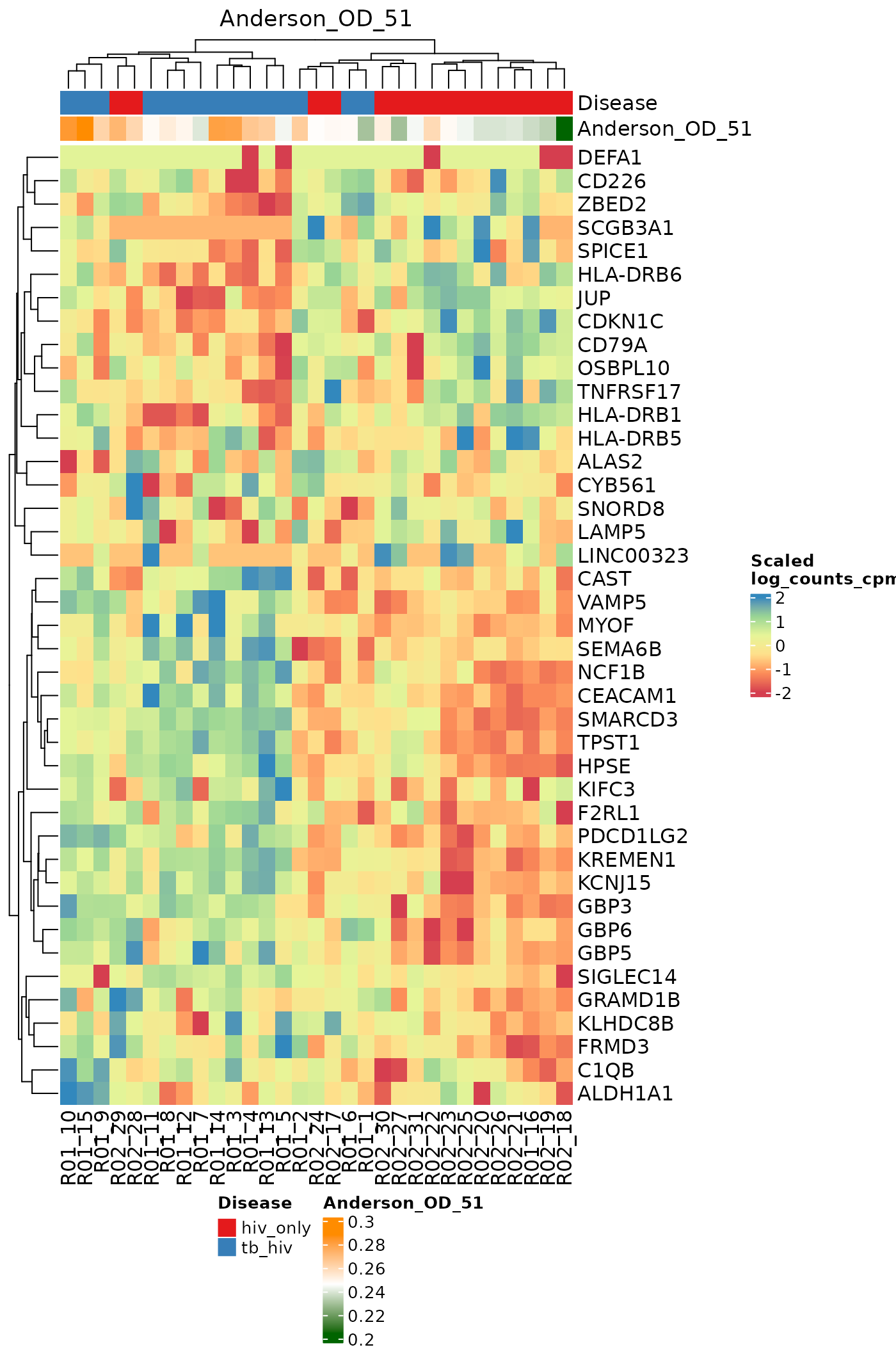
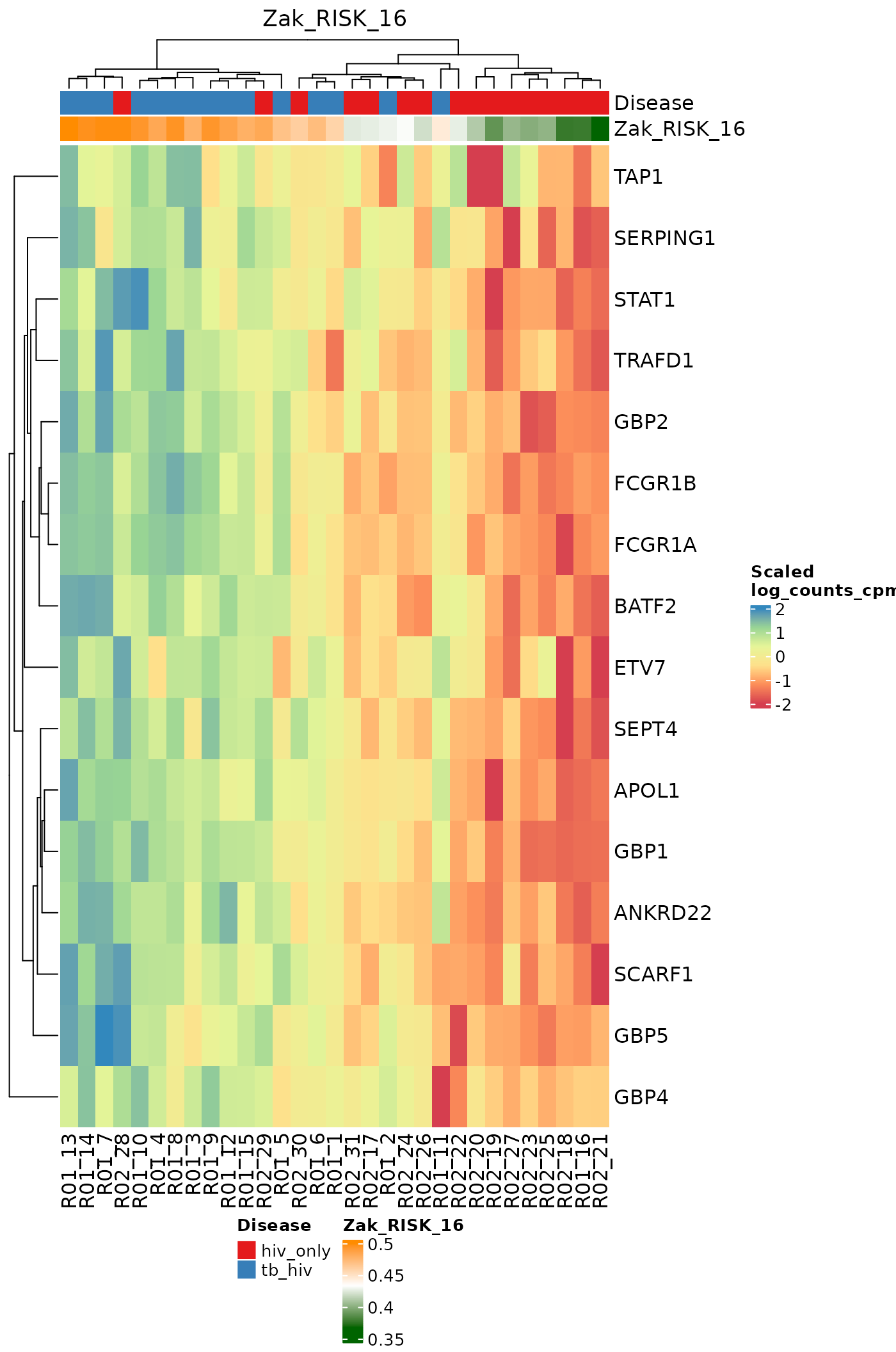
Heatmaps for Individual Signatures
The signatureGeneHeatmap function produces heatmaps that
highlight a single selected signature. The resulting plots feature
samples on the columns, and the genes in the signature on the rows. The
annotation rows at the top are related to both the disease phenotype and
to the signature score itself. The gradient of the heatmap is created
using the gene expression values in the assay specified by the
useAssay parameter. Here, we observe how the log(CPM)
values for specific genes relate to the signature score for each sample
using the signatures Anderson_42, Anderson_OD_51, and Zak_RISK_16.
for (i in sigs){
cat("####", i, "\n")
signatureGeneHeatmap(inputData = ssgsea_result, useAssay = "log_counts_cpm",
TBsignatures[sigs][[i]],
name = i, signatureColNames = i,
annotationColNames = c("Disease"),
showColumnNames = TRUE,
choose_color = col.me)
cat("\n\n")
}
Compare scoring methods for a single signature
The compareAlgs function allows multiple scoring methods
to be compared via a heatmap or boxplot with samples on the columns and
methods on the rows. Here, we compare scoring methods for the
“Tabone_RES_25” signature. It seems that singscore may be the best
method here, as its sample scores most closely align with the
information provided by the annotation data.
An examination of the boxplot and heatmap together determine that PLAGE and the comparing Z-score methods are least helpful in correctly identifying TB from LTBI subjects, although still quite good - average AUC scores are a little less than 0.8 and subjects in different groups are falsely assigned similar scores. According to the boxplot, we see that singscore has the highest predictive AUC next to ssGSEA.
# Heatmap
compareAlgs(hivtb_data, annotationColName = "Disease",
scale = TRUE,
algorithm = c("GSVA", "ssGSEA",
"singscore", "PLAGE", "Zscore"),
useAssay = "log_counts",
signatures = TBsignatures["Tabone_RES_25"],
choose_color = col.me, show.pb = FALSE,
parallel.sz = 1)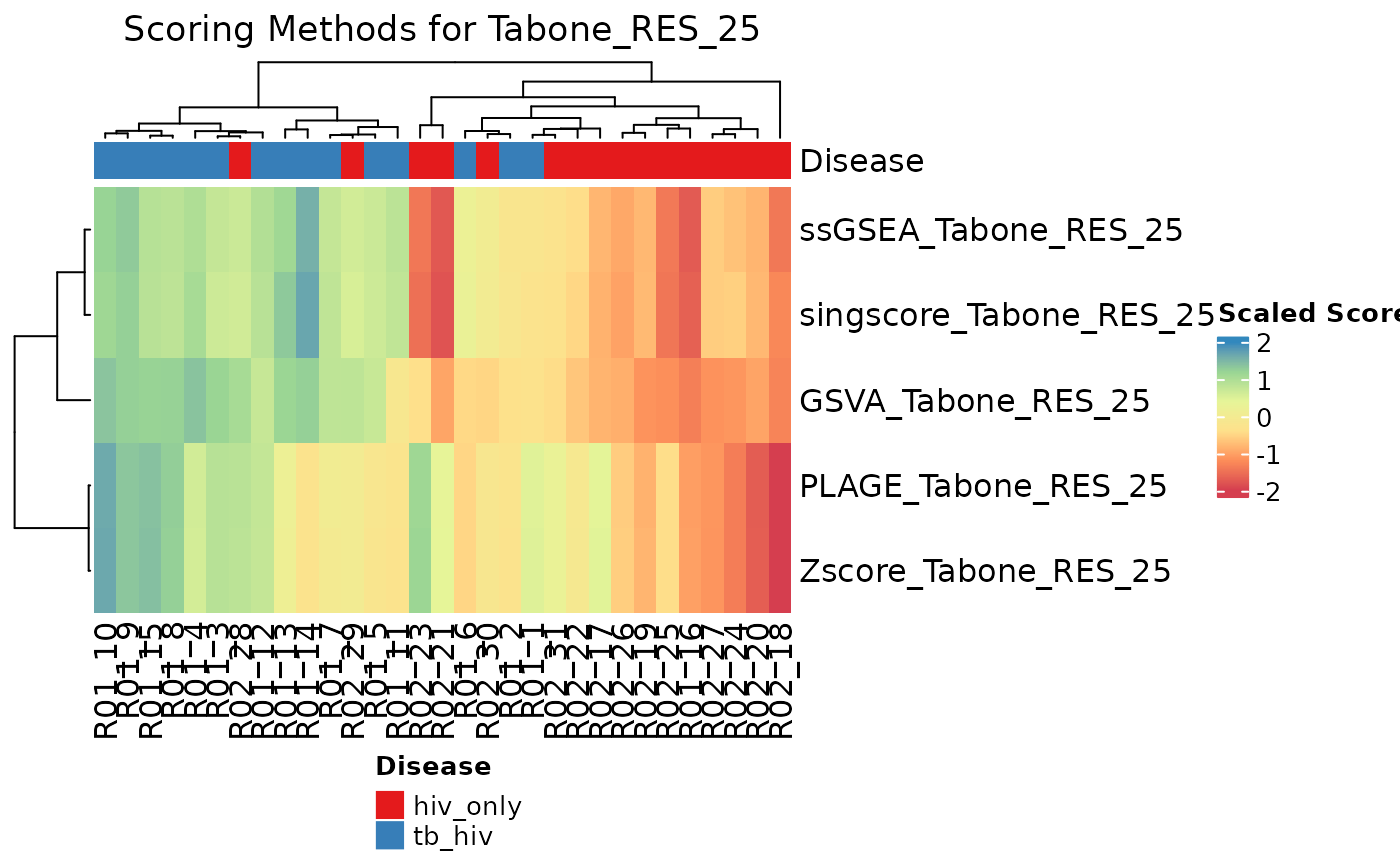
# Boxplot
compareAlgs(hivtb_data, annotationColName = "Disease",
scale = TRUE,
algorithm = c("GSVA", "ssGSEA",
"singscore", "PLAGE", "Zscore"),
useAssay = "log_counts",
signatures = TBsignatures["Tabone_RES_25"],
choose_color = col.me, show.pb = FALSE,
parallel.sz = 1, output = "boxplot")
Comparing scores via bootstrapped AUCs
Table with T-tests & AUC
The TableAUC function creates a table of useful
information regarding the scored signatures. First, a 2-sample t-test is
conducted on the scores with the TB/HIV status as the response variable.
This is intended to give one metric of whether the signature is a
valuable identifier of the disease phenotype. The log-scaled p-values
are provided for easier means of comparison.
The table also gives the AUC values for the signature scores, along with confidence intervals derived from bootstrapping. Most AUC estimates are fairly high.
Boxplots for the bootstrapped AUCs
We can visualize the bootstrapped AUCs for the scored signatures by creating a collection of boxplots.
compareBoxplots(ssgsea_result, annotationColName = "Disease",
signatureColNames = names(TBsignatures),
pb.show = FALSE, rotateLabels = TRUE)
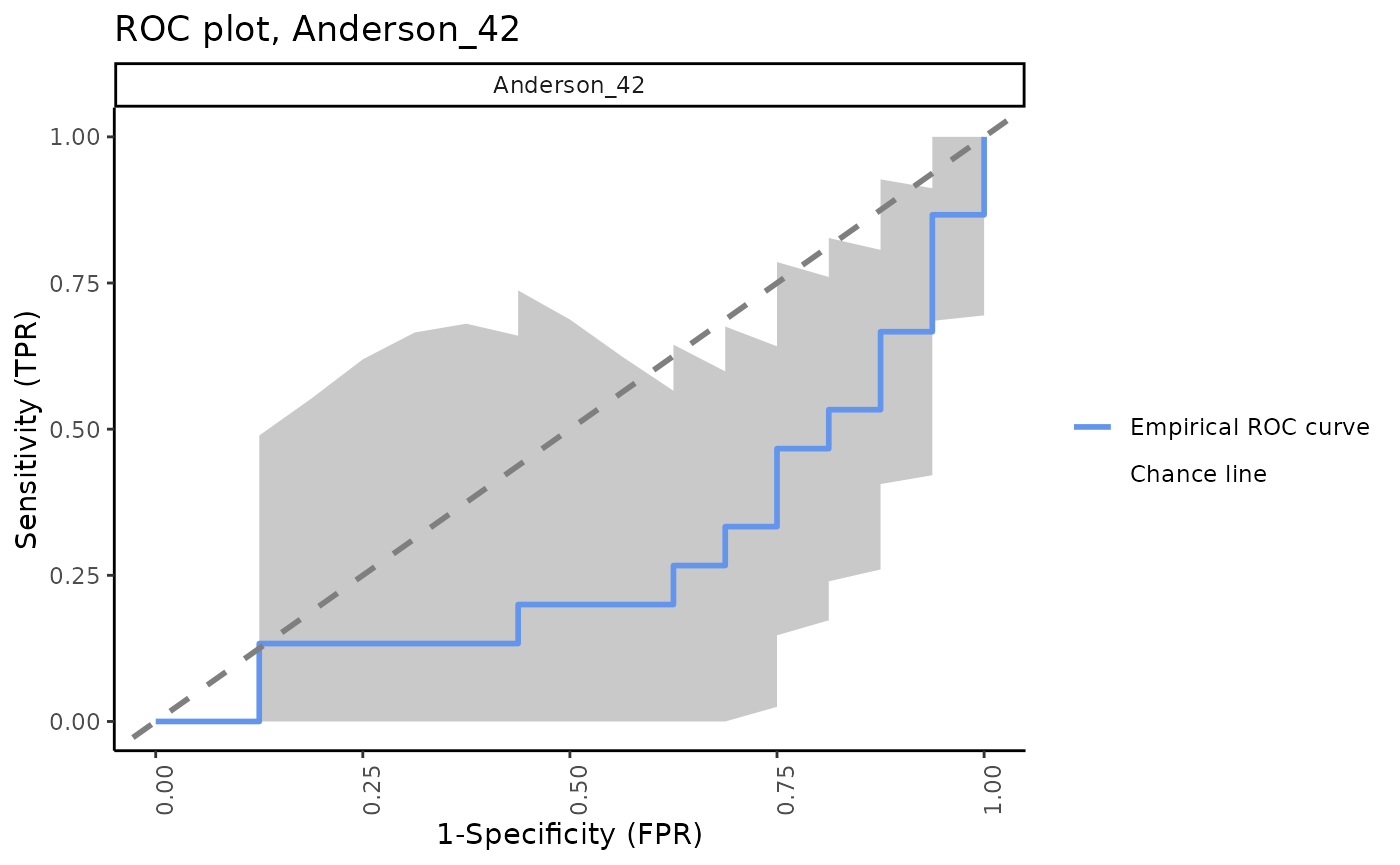
ROC plots for all signatures with 95% CI bands
The signatureROCplot_CI function plots the ROC curves
for signature scores in separate plots, along with CI bands for the
specified level of confidence. The signatureROCplot
function is similar, but does not include confidence interval bands.
Note that, in some cases, signatures will be positive identifiers of TB whereas others are negative identifiers, hence some ROC curves will be below the chance line.
signatureROCplot_CI(inputData = ssgsea_result,
signatureColNames = names(TBsignatures),
annotationColName = "Disease", pb.show = FALSE)
Separate ROC plots, 95% CI bands
for (i in sigs){
cat("####", i, "\n")
print(signatureROCplot_CI(inputData = ssgsea_result,
signatureColNames = i,
annotationColName = "Disease",
name = paste("ROC plot,", i, sep = " "), pb.show = FALSE))
cat("\n\n")
}
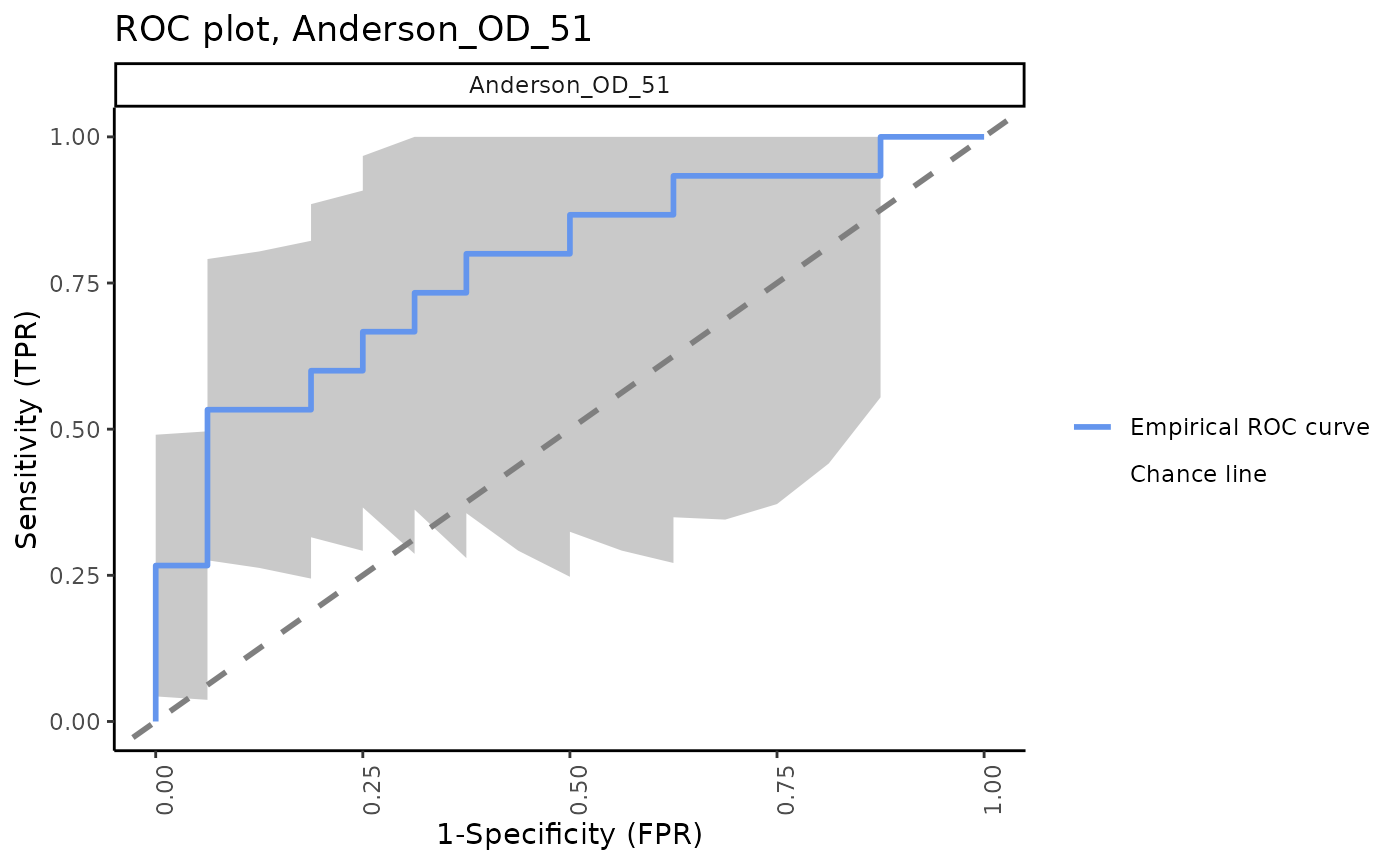
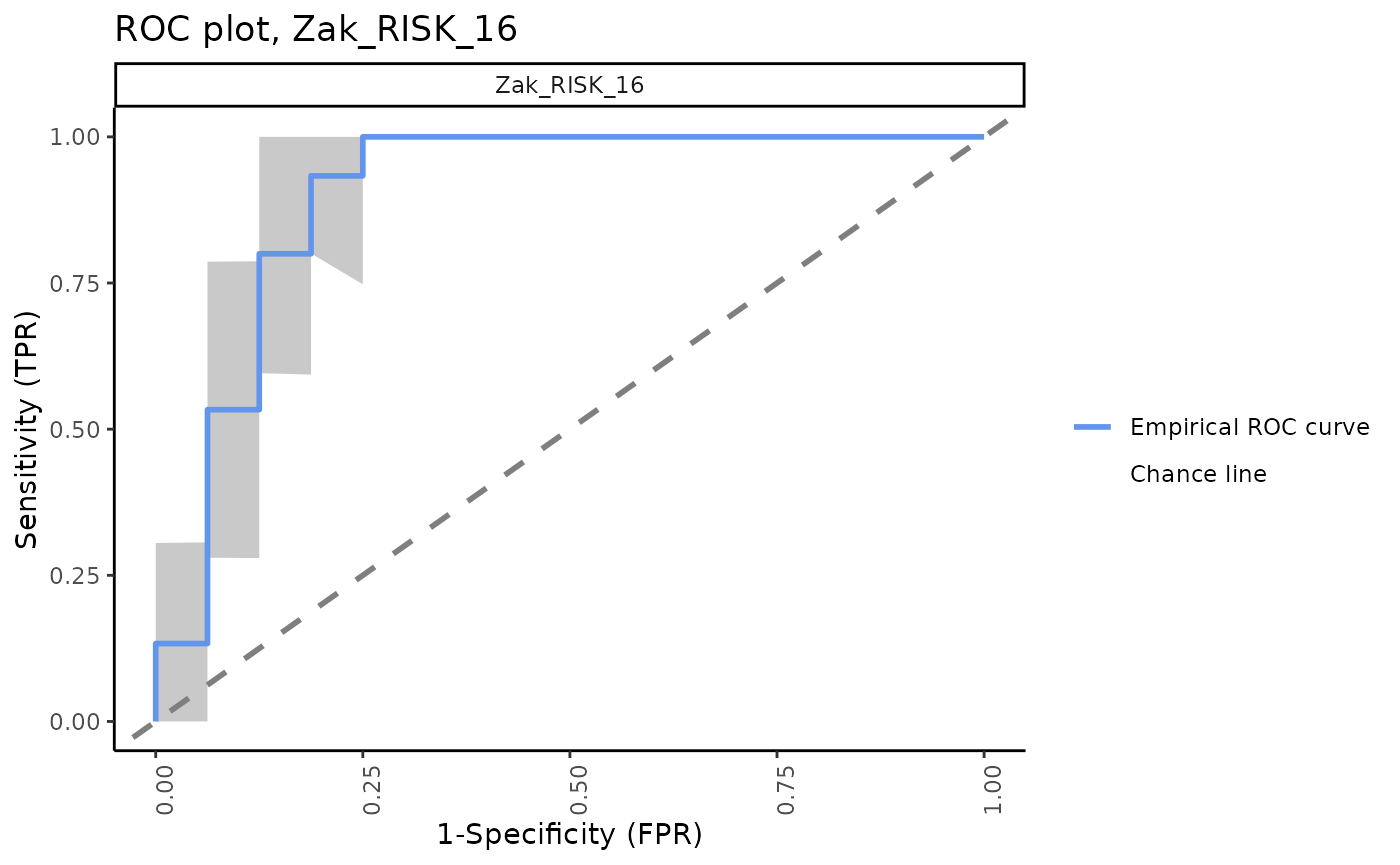
Signature Evaluation with Logistic Regression
Another method of signature evaluation featured in the
TBSignatureProfiler package is available with the
SignatureQuantitative function.
During the training process, we bootstrap the samples, cross-validate the logistic regression prediction of the TB HIV status of each sample, and calculate the validation set AUCs from each cross-validation iteration. In theory, if a signature is a useful predictor of status, it should have a higher average AUC from these logistic regression bootstraps.
### Make an additional binary indicator for signature evaluation
hivtb_data$BinaryTB <- as.numeric(hivtb_data$Disease) - 1
## We can normalize the data and evaluate the signatures
hivtb_norm <- deseq2_norm_rle(assay(hivtb_data, "counts"))
quantitative.result <- SignatureQuantitative(hivtb_norm,
targetVec.num = colData(hivtb_data)$BinaryTB,
signature.list = TBsignatures[sigs],
signature.name.vec = sigs,
num.boot = 3,
pb.show = FALSE)We also create a boxplot of AUC for each signature, which provides a clear comparison between the signatures.
plotQuantitative(hivtb_norm, targetVec.num = colData(hivtb_data)$BinaryTB,
signature.list = TBsignatures[sigs],
signature.name.vec = sigs,
num.boot = 3, pb.show = FALSE, rotateLabels = TRUE)
Table of Specificity Results
DT::datatable(round(quantitative.result$df.specificity.ci, 4),
options = list(scrollX = TRUE, pageLength = 10),
rownames = FALSE)## R version 4.4.3 (2025-02-28)
## Platform: x86_64-pc-linux-gnu
## Running under: AlmaLinux 8.10 (Cerulean Leopard)
##
## Matrix products: default
## BLAS/LAPACK: FlexiBLAS NETLIB; LAPACK version 3.11.0
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
##
## time zone: America/New_York
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats4 stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] TBSignatureProfiler_1.21.1 SummarizedExperiment_1.36.0
## [3] Biobase_2.66.0 GenomicRanges_1.58.0
## [5] GenomeInfoDb_1.42.3 IRanges_2.40.1
## [7] S4Vectors_0.44.0 BiocGenerics_0.52.0
## [9] MatrixGenerics_1.18.1 matrixStats_1.5.0
## [11] BiocStyle_2.34.0
##
## loaded via a namespace (and not attached):
## [1] splines_4.4.3 tibble_3.2.1
## [3] hardhat_1.4.1 graph_1.84.1
## [5] pROC_1.18.5 XML_3.99-0.18
## [7] rpart_4.1.24 lifecycle_1.0.4
## [9] edgeR_4.4.2 doParallel_1.0.17
## [11] globals_0.16.3 lattice_0.22-6
## [13] MASS_7.3-65 crosstalk_1.2.1
## [15] magrittr_2.0.3 limma_3.62.2
## [17] sass_0.4.10 rmarkdown_2.29
## [19] jquerylib_0.1.4 yaml_2.3.10
## [21] ROCit_2.1.2 HGNChelper_0.8.15
## [23] DBI_1.2.3 RColorBrewer_1.1-3
## [25] lubridate_1.9.4 abind_1.4-8
## [27] zlibbioc_1.52.0 purrr_1.0.4
## [29] nnet_7.3-20 ipred_0.9-15
## [31] circlize_0.4.16 lava_1.8.1
## [33] GenomeInfoDbData_1.2.13 irlba_2.3.5.1
## [35] listenv_0.9.1 gdata_3.0.1
## [37] GSVA_2.0.7 annotate_1.84.0
## [39] parallelly_1.43.0 pkgdown_2.1.1
## [41] codetools_0.2-20 DelayedArray_0.32.0
## [43] DT_0.33 tidyselect_1.2.1
## [45] shape_1.4.6.1 UCSC.utils_1.2.0
## [47] farver_2.1.2 ScaledMatrix_1.14.0
## [49] jsonlite_2.0.0 caret_7.0-1
## [51] GetoptLong_1.0.5 e1071_1.7-16
## [53] survival_3.8-3 iterators_1.0.14
## [55] systemfonts_1.2.1 foreach_1.5.2
## [57] tools_4.4.3 ragg_1.3.3
## [59] Rcpp_1.0.14 glue_1.8.0
## [61] prodlim_2024.06.25 SparseArray_1.6.2
## [63] xfun_0.52 DESeq2_1.46.0
## [65] dplyr_1.1.4 HDF5Array_1.34.0
## [67] withr_3.0.2 BiocManager_1.30.25
## [69] fastmap_1.2.0 rhdf5filters_1.18.1
## [71] digest_0.6.37 rsvd_1.0.5
## [73] timechange_0.3.0 R6_2.6.1
## [75] textshaping_1.0.0 colorspace_2.1-1
## [77] Cairo_1.6-2 gtools_3.9.5
## [79] dichromat_2.0-0.1 RSQLite_2.3.9
## [81] tidyr_1.3.1 generics_0.1.3
## [83] data.table_1.17.99 recipes_1.2.1
## [85] class_7.3-23 httr_1.4.7
## [87] htmlwidgets_1.6.4 S4Arrays_1.6.0
## [89] ModelMetrics_1.2.2.2 pkgconfig_2.0.3
## [91] gtable_0.3.6 timeDate_4041.110
## [93] blob_1.2.4 ComplexHeatmap_2.22.0
## [95] SingleCellExperiment_1.28.1 XVector_0.46.0
## [97] htmltools_0.5.8.1 bookdown_0.42
## [99] GSEABase_1.68.0 clue_0.3-66
## [101] scales_1.4.0 png_0.1-8
## [103] SpatialExperiment_1.16.0 gower_1.0.2
## [105] knitr_1.50 rstudioapi_0.17.1
## [107] reshape2_1.4.4 rjson_0.2.23
## [109] nlme_3.1-167 proxy_0.4-27
## [111] cachem_1.1.0 rhdf5_2.50.2
## [113] GlobalOptions_0.1.2 stringr_1.5.1
## [115] parallel_4.4.3 AnnotationDbi_1.68.0
## [117] desc_1.4.3 pillar_1.10.2
## [119] grid_4.4.3 vctrs_0.6.5
## [121] BiocSingular_1.22.0 beachmat_2.22.0
## [123] xtable_1.8-4 cluster_2.1.8
## [125] evaluate_1.0.3 singscore_1.26.0
## [127] magick_2.8.6 cli_3.6.5
## [129] locfit_1.5-9.12 compiler_4.4.3
## [131] rlang_1.1.6 crayon_1.5.3
## [133] future.apply_1.11.3 labeling_0.4.3
## [135] plyr_1.8.9 fs_1.6.6
## [137] stringi_1.8.7 BiocParallel_1.40.0
## [139] Biostrings_2.74.1 glmnet_4.1-8
## [141] Matrix_1.7-3 sparseMatrixStats_1.18.0
## [143] bit64_4.6.0-1 future_1.34.0
## [145] ggplot2_3.5.2 Rhdf5lib_1.28.0
## [147] KEGGREST_1.46.0 statmod_1.5.0
## [149] memoise_2.0.1 bslib_0.9.0
## [151] bit_4.6.0 splitstackshape_1.4.8